

Управление инцидентами для высокоскоростных команд
MTBF, MTTR, MTTA и MTTF
Понимание некоторых из наиболее распространенных метрик инцидентов
В современном постоянно движущемся мире сбои в работе и технические инциденты становятся как никогда важными. Ошибки и простои ведут к реальным последствиям. Пропущенные сроки. Задержки оплаты. Задержки работы по проектам.
Вот почему для компаний важно количественно оценивать и отслеживать показатели безотказной работы, времени простоя и того, как быстро и эффективно команды решают проблемы.
Некоторые из наиболее часто отслеживаемых в отрасли метрик: MTBF (средняя наработка на отказ), MTTR (среднее время восстановления, исправления, реагирования или устранения), MTTF (средняя наработка до отказа) и MTTA (среднее время подтверждения) — эти метрики предназначены для того, чтобы помочь техническим командам понять, как часто происходят инциденты и как быстро команда справляется с ними.
Многие эксперты спорят о действительной пользе этих метрик, если использовать их в отрыве от остальных показателей, потому что они не дают ответа на сложные вопросы о том, как устраняются инциденты, что работает, а что нет, и как, когда и почему проблемы обостряются или ослабляются.
С другой стороны, MTTR, MTBF и MTTF могут быть хорошей основой или эталоном, с которых стоит начинать обсуждение более глубоких и важных вопросов.

Как профессионалы реагируют на крупные инциденты
Получите наше бесплатное руководство по управлению инцидентами. Изучите все инструменты и методы, которые Atlassian использует для управления крупными инцидентами.
Оговорка об MTTR
Говоря об MTTR, можно предположить, что это один показатель с одним значением. В действительности за ним скрываются четыре разных показателя. «R» может означать решение (repair), реагирование (respond), устранение (resolve) или восстановление (recovery), и хотя эти четыре показателя перекрываются, каждый имеет собственный смысл и особенности.
Поэтому если вашей команде нужно отслеживать MTTR, рекомендуется уточнить, какой именно MTTR имеется в виду и как его определить. Прежде чем вы начнете отслеживать успехи и неудачи, у вашей команды должно быть общее понимание того, что именно вы отслеживаете.
MTBF: средняя наработка на отказ
Что такое средняя наработка на отказ?
MTBF (средняя наработка на отказ) — это среднее время между исправляемыми сбоями технологического продукта. Эта метрика используется для отслеживания как доступности, так и надежности продукта. Чем больше времени проходит между отказами, тем надежнее система.
Цель для большинства компаний — сохранить наработку на отказ как можно выше, достигнув сотни тысяч (или даже миллионов) часов между инцидентами.
Как рассчитать среднюю наработку на отказ
MTBF рассчитывается с использованием среднего арифметического. По сути, вы должны взять данные за период, на который вы хотите рассчитать MTBF (можно за шесть месяцев, год, за пять лет), и поделить общее время работы за этот период на количество сбоев.
Итак, предположим, что мы оцениваем 24-часовой период и за этот период мы потеряли два часа из-за двух отдельных инцидентов. Наше общее время безотказной работы составляет 22 часа. Разделим на два и получаем 11 часов. Итак, наша наработка на отказ составляет 11 часов.
Поскольку эта метрика используется для отслеживания надежности, наработка на отказ не учитывает ожидаемое время простоя во время планового технического обслуживания. Вместо этого она фокусируется на неожиданных простоях и проблемах.
Происхождение понятия средней наработки на отказ
MTBF берет свое начало в авиационной отрасли, где системные сбои означают особенно серьезные последствия не только с точки зрения стоимости, но и человеческой жизни. С тех пор эта аббревиатура пробралась в различные технические и механические отрасли промышленности и особенно часто используется в производстве.
Как и когда использовать среднюю наработку на отказ
Время наработки на отказ полезно для покупателей, которые хотят быть уверены, что получают самый надежный продукт, полетят на самом надежном самолете или выберут самое безопасное производственное оборудование для своего завода.
Для внутренних команд эта метрика помогает выявлять проблемы и отслеживать успехи и неудачи. Она также может помочь компаниям разработать подробные рекомендации для клиентов, чтобы они знали, когда они должны заменить деталь, обновить систему или принести продукт на техническое обслуживание.
MTBF — это метрика для сбоев в восстанавливаемых системах. Для сбоев, требующих замены системы, обычно используют термин MTTF (средняя наработка до отказа).
Например, представьте двигатель автомобиля. При расчете времени между внеплановыми техническими обслуживаниями двигателя следует использовать MTBF (среднюю наработку на отказ). При расчете времени до полной замены двигателя вы должны использовать MTTF (среднюю наработку до отказа).
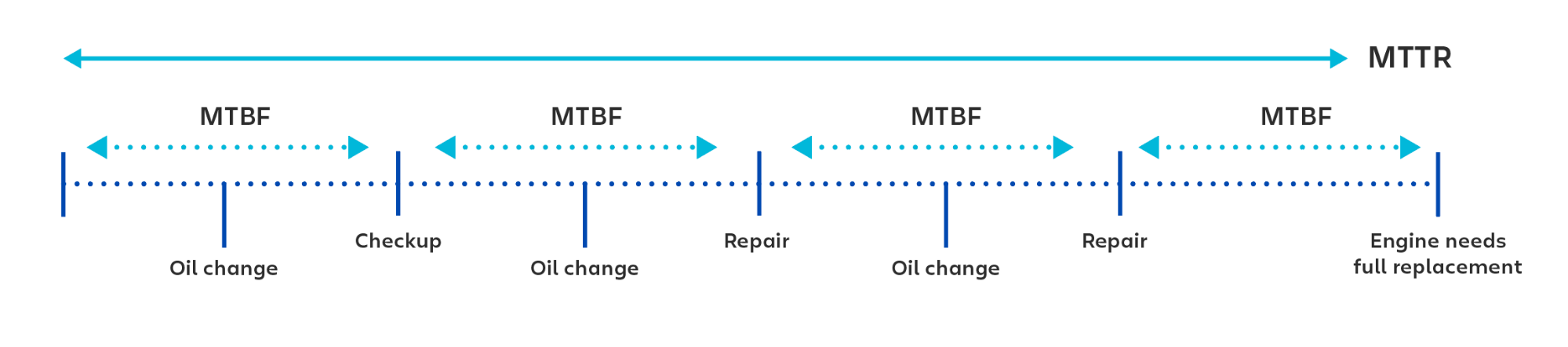
MTTR: среднее время исправления
Что такое среднее время исправления?
MTTR (среднее время ремонта) — это среднее время, необходимое для ремонта системы (обычно технического или механического). Оно включает в себя как время ремонта, так и любое время тестирования. В этой метрике учитывается все время до тех пор, пока система не будет снова полностью работоспособна.
Как рассчитать среднее время исправления
Вы можете рассчитать MTTR, суммируя общее время, затраченное на ремонт в течение любого заданного периода, а затем разделив это время на количество ремонтов.
Итак, предположим, мы считаем эту метрику для ремонта в течение недели. За это время было 10 простоев, и системы активно ремонтировались в течение четырех часов. Четыре часа — это 240 минут. 240 делим на 10 и получаем 24. Что означает, что среднее время ремонта в этом случае будет составлять 24 минуты.
Ограничения среднего времени исправления
Среднее время ремонта не всегда совпадает с тем же временем, что и время сбоя работы системы. В некоторых случаях ремонт начинается в течение нескольких минут после сбоя продукта или сбоя системы. В других случаях между собственно инцидентом, обнаружением инцидента и началом ремонта бывает некоторая задержка.
Эта метрика наиболее полезна при отслеживании того, как быстро обслуживающий персонал может устранить проблему. Она не предназначена для выявления проблем с системными оповещениями или задержками перед восстановлением, которые также являются важными факторами при оценке успехов и сбоев программы управления инцидентами.
Как и когда использовать среднее время исправления
MTTR — это метрика, которую используют команды поддержки и технического обслуживания для обеспечения восстановительных работ на нужном уровне. Цель состоит в том, чтобы этот показатель был как можно ниже за счет повышения эффективности процессов восстановления и продуктивности команд.
MTTR: среднее время восстановления
Что такое среднее время восстановления?
MTTR (среднее время восстановления или среднее время стабилизации) — это среднее время восстановления после сбоя работы продукта или системы. Оно включает в себя полное время простоя с момента выхода из строя системы или продукта до момента, когда они снова становятся полностью работоспособными.
Это основной показатель DevOps, который, по мнению программы DevOps Research and Assessment (DORA), можно использовать для оценки стабильности команды DevOps.
Как рассчитать среднее время восстановления
Среднее время восстановления рассчитывается путем суммирования всего времени простоя в работе за определенный период и деления его на количество инцидентов. Итак, предположим, что наши системы были отключены на 30 минут в течение двух отдельных инцидентов за 24-часовой период. 30 делим на два, получаем 15, так что наш MTTR составляет 15 минут.
Ограничения среднего времени восстановления
MTTR используется для измерения скорости полного процесса восстановления. Достаточно ли она высокая? А по сравнению с вашими конкурентами?
Эта общая метрика помогает определить, есть ли у вас проблемы. Однако если вы хотите диагностировать, в какой именно части вашего процесса есть проблема (проблема в вашей системе оповещений? команда слишком много времени работает над исправлением? кто-то слишком долго отвечает на запрос на исправление?), то вам понадобится больше данных. Потому что между сбоем и восстановлением может произойти много чего.
Проблема может быть связана с вашей системой оповещения. Существует ли задержка между сбоем и отправкой оповещения? Достаточно ли быстро оповещения доходят до нужного человека?
Проблема может быть в диагностике. Можете ли вы быстро выяснить, в чем проблема? Существуют ли процессы, которые можно было бы улучшить?
Или проблема может быть с самим процессом исправления. Достаточно ли эффективны ваши команды технического обслуживания? Если они тратят все свое время на исправление, то что именно их тормозит?
Вам нужно будет копнуть глубже, чем MTTR, чтобы ответить на эти вопросы, но среднее время восстановления может стать отправной точкой для диагностики того, существует ли проблема в процессе восстановления и требует ли она более глубокого анализа.
Как и когда использовать среднее время восстановления
MTTR является хорошей метрикой для оценки скорости общего процесса восстановления.
MTTR: среднее время разрешения
Что такое среднее время разрешения?
MTTR (среднее время разрешения) — это среднее время, необходимое для полного устранения сбоя. Оно включает в себя не только время, затраченное на обнаружение сбоя, диагностику проблемы и ее устранение, но и время, затраченное на предотвращение повторения проблемы.
Эта метрика расширяет ответственность команды, обрабатывающей исправление: она задает ожидания в плане повышения ее продуктивности в долгосрочной перспективе. В этом и заключается разница между простым тушением пожара и тушением пожара с последующей установкой противопожарной системы.
Существует сильная связь между этим MTTR и удовлетворенностью клиентов, так что этой метрике нужно уделить особое внимание.
Как рассчитать среднее время разрешения
Чтобы рассчитать этот MTTR, рассчитайте полное время разрешения в течение периода, который вы хотите отслеживать, и разделите на количество инцидентов.
Таким образом, если ваши системы были отключены в общей сложности 2 часа за 24-часовой период из-за одного инцидента и команды потратили еще 2 часа на исправление, чтобы гарантировать, что сбой системы не повторится, в сумме получается 4 часа, потраченных на решение проблемы. Это означает, что ваш MTTR составляет 4 часа.
Заметка об отслеживании среднего времени разрешения
Имейте в виду, что MTTR чаще всего рассчитывается с использованием рабочих часов (поэтому если вы восстановите работу в конце рабочего дня и потратите время на исправление основной проблемы первым делом на следующее утро, ваш MTTR не будет включать 16 часов, в течение которых вы не работали). Если у вас есть команды в разных часовых поясах и вы работаете круглосуточно или если у вас есть дежурные сотрудники, работающие во внеурочное время, важно определить, как вы будете отслеживать время для этой метрики.
Как и когда использовать среднее время разрешения
MTTR обычно используется, когда речь идет о незапланированных инцидентах, а не о запросах на обслуживание (которые обычно планируются).
MTTR: среднее время реагирования
Что такое среднее время реагирования?
MTTR (среднее время реагирования) — это среднее время, необходимое для восстановления после сбоя продукта или системы с момента первого оповещения об этом сбое. Оно не включает время задержки в вашей системе оповещения.
Как рассчитать среднее время реагирования
Чтобы рассчитать этот MTTR, рассчитайте полное время отклика с момента получения оповещения до того, когда продукт или услуга снова полностью функционируют. Затем разделите его на количество инцидентов.
Например: если у вас было 4 инцидента за 40-часовую рабочую неделю и вы потратили на них 1 час (от оповещения до исправления), то MTTR за эту неделю будет составлять 15 минут.
Как и когда использовать среднее время реагирования
MTTR часто используется в кибербезопасности при измерении успеха команды в нейтрализации атак на систему.
MTTA: среднее время подтверждения
Что такое среднее время подтверждения?
MTTA (среднее время подтверждения) — это среднее время, которое проходит с момента отправки оповещения до начала работы над исправлением. Эта метрика полезна для измерения скорости реагирования вашей команды и эффективности вашей системы оповещения.
Как рассчитать среднее время подтверждения
Чтобы рассчитать MTTA, посчитайте время между отправкой оповещения и подтверждением его получения, а затем разделите на количество инцидентов.
Например: если у вас было 10 инцидентов и в общей сложности прошло 40 минут между отправкой оповещения и подтверждением его получения для всех 10, вы поделите 40 на 10 и получите в среднем 4 минуты.
Как и когда использовать среднее время подтверждения
Метрика MTTA полезна для отслеживания отзывчивости. Ваша команда устала от оповещений и слишком долго отвечает на сообщения об инцидентах? Эта метрика поможет вам обнаружить и проанализировать эту проблему.
MTTF: средняя наработка до отказа
Что такое средняя наработка до отказа?
MTTF (средняя наработка до отказа) — среднее время между неремонтируемыми отказами технологического продукта. Например, если автомобильные двигатели марки X исправно работают в среднем 500 000 часов, до того как они полностью выйдут из строя и будут подлежать замене, MTTF двигателей будет составлять 500 000.
Эта метрика помогает понять, как долго система будет исправно работать, и определить, превосходит ли новая версия системы старую. Метрика позволяет предоставить клиентам информацию об ожидаемом сроке исправной работы и о том, когда следует запланировать проверку системы.
Как рассчитать среднюю наработку до отказа
Средняя наработка до отказа — это среднее арифметическое, которое определяется как сумма общего времени работы оцениваемых продуктов, деленная на общее количество устройств.
Например: предположим, вы рассчитываете MTTF лампочек. Как долго лампочки бренда Y в среднем работают, прежде чем они перегорают? Далее предположим, что для расчета у вас есть четыре лампочки (если вам нужны статистически значимые данные, вам понадобится гораздо больше, но, чтобы не перегружать вас расчетами, давайте возьмем всего четыре).
Лампочка А горит 20 часов. Лампочка B — 18. Лампочка C —21. И лампочка D —21 час. Это в общей сложности 80 часов горения лампочки. Делим на четыре и получаем MTTF в 20 часов.

Проблема, связанная со средней наработкой до отказа
Для таких случаев, как лампочки, смысл MTTF совершенно ясен. Мы можем включить лампочки и ждать до тех пор, пока не перегорит последняя, а затем использовать полученную информацию, чтобы сделать выводы о времени работы наших лампочек.
Но что происходит, когда мы измеряем что-то, что не перегорает так быстро? Что-то, что должно бесперебойно работать в течение долгих лет? Хотя MTTF часто используется и для этих случаев, эта метрика — не лучший выбор. Потому что мы не держим продукт включенным до тех пор, пока он не выйдет из строя; в основном мы запускаем продукт на определенный период времени и измеряем количество выходов из строя.
Например: предположим, что мы пытаемся получить статистику MTTF на планшетах бренда Z. Планшеты по-хорошему рассчитаны на долгие годы, но у бренда Z есть всего шесть месяцев для сбора данных. Поэтому тестируют 100 планшетов в течение шести месяцев. Допустим, один планшет ломается ровно на шестимесячной отметке.
Итак, мы умножаем общее время работы (полгода, умноженное на 100 планшетов) и получаем 600 месяцев. Только один планшет вышел из строя, так что мы разделим значение на один, и наш MTTR будет составлять 600 месяцев, то есть 50 лет.
Прослужат ли планшеты Brand Z в среднем 50 лет каждый? Маловероятно. И поэтому эта метрика не подходит в таких случаях.
Как и когда использовать среднюю наработку до отказа
MTTF хорошо работает, когда вы пытаетесь оценить средний срок службы продуктов и систем с коротким сроком службы (например, лампочек). Показатель предназначен только для случаев, когда оценивается полное прекращение работы продукта. При расчете времени между инцидентами, требующими восстановления, предпочтительной аббревиатурой является MTBF (средняя наработка на отказ).
MTBF, MTTR, MTTF и MTTA
Итак, какую метрику лучше использовать, когда дело доходит до отслеживания и улучшения управления инцидентами?
Ответ — все.
Хотя они иногда используются взаимозаменяемо, каждая метрика позволяет рассмотреть ситуацию с разных сторон. При совместном использовании они могут показать более полную картину и дать вам понять, насколько успешна ваша команда в управлении инцидентами и что она может улучшить.
Среднее время восстановления показывает, как быстро у вас получается возобновить работу ваших систем.
Рассчитайте среднее время реагирования, и вы получите представление о том, сколько времени восстановления тратится на работу вашей команды и сколько — на получение оповещения.
Потом рассчитайте среднее время исправления, и вы поймете, сколько времени команда тратит на исправление, а сколько на диагностику.
Теперь рассчитайте среднее время разрешения, и вы начнете понимать весь процесс исправления и решения проблем, выходящий за рамки самого простоя, который они вызывают.
Посчитайте среднюю наработку на отказ, и картина станет еще шире: вы увидите, насколько успешна ваша команда в предотвращении или сокращении будущих проблем.
А затем добавьте среднюю наработку до отказа, чтобы понять полный жизненный цикл продукта или системы.
Jira Service Management предлагает возможности создания отчетов, чтобы ваша команда могла отслеживать KPI, а также контролировать и оптимизировать управление инцидентами.
Рассмотренные продукты
Своевременно уведомляйте нужных людей за счет централизованных оповещений.
Изучайте информирование об инцидентах с помощью Statuspage
В этом руководстве мы покажем, как использовать шаблоны инцидентов, чтобы наладить эффективную коммуникацию во время разрешения инцидента. Применимо ко многим видам технических сбоев.
Читать учебное руководствоШаблоны и примеры информирования об инцидентах
Во время реагирования на инциденты становится ясна ценность шаблонов сообщений. Загрузите шаблоны, которые использует наша команда, и познакомьтесь с другими примерами распространенных инцидентов.
Читать статью