

Управление инцидентами для высокоскоростных команд
Как выбрать ключевые показатели эффективности и метрики управления инцидентами
Отслеживание и совершенствование управления инцидентами с течением времени
В современном мире непрерывной работы систем технические инциденты ведут к серьезным последствиям.
Каждый час простоя в работе системы обходится компаниям в среднем в 300 тысяч долларов США упущенной выгоды, потерянной производительности сотрудников и расходов на техническое обслуживание. В случае масштабных отказов издержки могут расти как на дрожжах (можно вспомнить компанию Delta Airlines, которая потеряла около 150 млн долларов США из-за сбоя в работе ИТ в 2017 году). Клиенты, которые не могут оплатить счета, провести важную видеоконференцию или купить авиабилет, быстро уходят к конкурентам.
На карту поставлено очень многое. Поэтому командам крайне важно отслеживать KPI управления инцидентами, а также использовать результаты для выявления, диагностики, исправления и, наконец, предотвращения инцидентов.
Положительный момент заключается в том, что при обработке инцидентов в веб-сфере и программном обеспечении (в отличие от механических поломок и отключения систем) команды обычно получают гораздо больше данных. Поэтому они могут эффективнее разобраться в ситуации и провести улучшение.
Но есть и минусы. Иногда становится сложнее понять проблему при наличии большого объема данных.
Ценность ключевых показателей эффективности, метрик и аналитики в управлении инцидентами
Ключевые показатели эффективности (KPI) помогают компаниям определить, достигают ли они конкретных целей. В контексте управления инцидентами этими показателями может быть количество инцидентов, среднее время разрешения или среднее время между инцидентами.
При отслеживании KPI управления инцидентами можно выявить и диагностировать проблемы с процессами и системами, определить ориентиры и поставить реалистичные цели для работы команды, а также найти отправную точку для решения масштабных вопросов.
Предположим, что компания стремится к разрешению всех инцидентов в течение 30 минут, но вашей команде это удается в среднем за 45 минут. Без конкретных показателей трудно понять, в чем проблема. Система оповещения срабатывает слишком медленно? В процессе что-то не работает? Нужны более современные диагностические инструменты? Эта проблема связана с командой или оборудованием?
Теперь добавьте показатели. Если точно известно, сколько времени требуется системе оповещения для срабатывания, вы сможете понять, является ли она причиной проблемы. Если диагностика занимает больше половины времени, вы можете сосредоточиться на устранении неполадок в ней. Если команда B работает на 25 % медленнее, чем команды A, C и D, можно попытаться понять, почему это происходит.
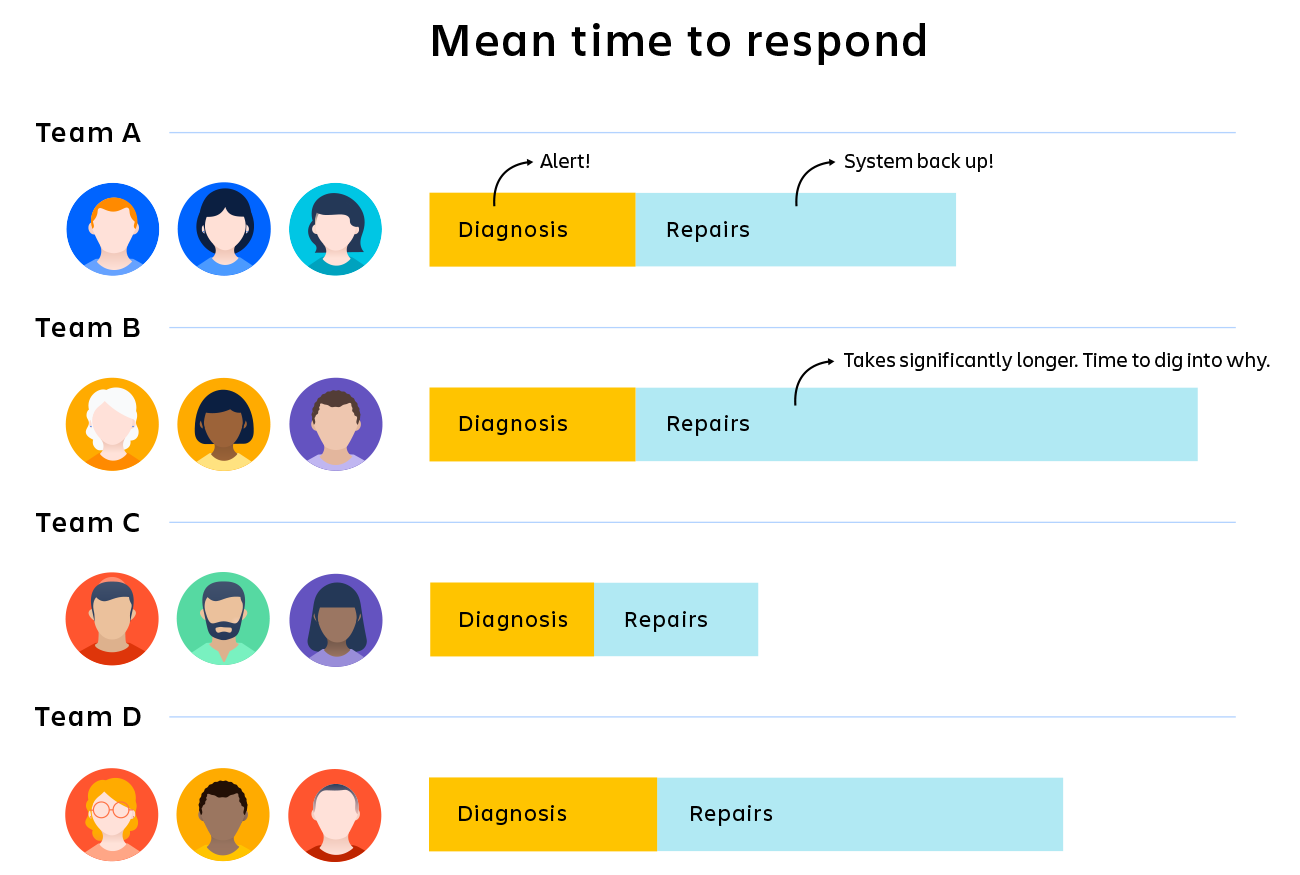
KPI не устранят ваши проблемы автоматически, но они помогут понять суть неполадок и укажут, куда нужно направить внимание и усилия.
Популярные KPI и метрики для управления инцидентами
Количество созданных оповещений
Если вы используете инструмент оповещения, полезно знать, сколько оповещений генерируется за определенный период времени. С помощью решения Jira Service Management вы сможете отправлять оповещения, а также создавать отчеты и дашбоарды для их отслеживания.
Ищите периоды, когда наблюдается значительный или нетипичный рост либо падение, а также положительная динамика. При обнаружении таких изменений проанализируйте причины и способы реагирования ваших команд на них.
Количество инцидентов за определенный период времени
Отслеживание количества инцидентов за определенный период времени подразумевает подсчет среднего числа инцидентов за определенный период. Этим периодом может быть неделя, месяц, квартал, год или даже день.
Со временем инциденты происходят чаще или реже? Количество инцидентов считается приемлемым или его можно сократить? После того как вы поймете, в чем заключается проблема с количеством инцидентов, вы сможете предположить, почему это число растет или остается высоким и что команда может сделать для решения проблемы.
MTBF
MTBF (средняя наработка на отказ) — среднее время работы технического продукта между устранимыми сбоями. С помощью этого показателя можно отслеживать доступность и надежность всех продуктов.
Как и другие показатели, он наводит на более серьезные вопросы. Если значение MTBF недостаточно высокое, стоит задуматься, почему системы так часто выходят из строя и как можно уменьшить число будущих сбоев или предотвратить их.
МТТА
MTTA (среднее время подтверждения) — это среднее время, которое проходит между получением оповещения и моментом, когда участник команды подтвердит инцидент и начнет работать над его устранением. Этот показатель важен тем, что с его помощью можно понять, насколько быстро ваша команда реагирует на инциденты.
Если выяснилось, что скорость реагирования недостаточно высокая, можно задать новые вопросы. Почему значение MTTA так велико? Команды перегружены, отвлекаются или не могут понять, кому адресовано оповещение? С помощью MTTA можно определить проблему, а подобные вопросы помогут добраться до ее сути.
MTTD
MTTD (среднее время обнаружения) — это среднее время, необходимое вашей команде, чтобы обнаружить проблему. Этот термин часто используется в сфере кибербезопасности командами, которые сосредоточены на обнаружении атак и случаев несанкционированного доступа.
Если значение этого показателя резко меняется или остается недостаточно высоким, стоит выяснить причину.
MTTR
MTTR может означать среднее время исправления, решения, реагирования или восстановления. Пожалуй, наибольшую пользу представляет среднее время решения. Этот показатель позволяет зафиксировать не только время, затраченное на диагностику и устранение непосредственной проблемы, но и время на предотвращение повторения такой проблемы в будущем. Восстановление является главным показателем DevOps; именно его, по мнению программы DevOps Research and Assessment (DORA), можно использовать для оценки стабильности команды DevOps.
Ценность этого показателя лучше всего проявляется во время диагностики. Разрешаются ли инциденты так быстро и эффективно, как вы ожидали? Если нет, нужно выяснить причину, по которой время разрешения не соответствует целевому значению.
Восстановление является главным показателем DevOps; именно его, по мнению программы DevOps Research and Assessment (DORA), можно использовать для оценки стабильности команды DevOps. Это совокупное время, которое уходит на обнаружение проблемы, смягчение ее последствий и полное устранение.
Время дежурства
Если у вас имеется ротация дежурных, рекомендуется отслеживать, сколько времени сотрудники и подрядчики тратят на вызов.С помощью этого показателя можно следить за тем, чтобы ни один сотрудник или команда не были перегружены.
С помощью Jira Service Management вы можете создавать исчерпывающие отчеты, чтобы мгновенно узнавать значения этих показателей.
sla
SLA (соглашение об уровне обслуживания) — это соглашение между поставщиком и клиентом об измеримых показателях, таких как время безотказной работы, время реагирования, а также мерах ответственности.
В этих соглашениях об уровне обслуживания фиксируются обещания компании (о времени безотказной работы, среднем времени восстановления и т. д.). Чтобы сдержать их, команды управления инцидентами должны отслеживать эти показатели. Если и когда значения таких показателей, как среднее время отклика или среднее время между сбоями, меняются, нужно обновить соглашения и (или) внести исправления (и это должно произойти быстро).
SLO
SLO (цель по уровню обслуживания) — это соглашение в рамках SLA о целевом значении того или иного показателя, например времени безотказной работы. Как и в случае с соглашением SLA, SLO являются важными показателями, которые нужно отслеживать, чтобы гарантировать, что компания выполняет свою часть соглашения в вопросах обслуживания клиентов.
Временная метка (или временная шкала)
Временная метка — это закодированная информация о том, что произошло в определенное время в ходе инцидента, до или после него. Такая информация обычно не считается показателем, но эти важные данные необходимо учитывать при оценке состояния управления инцидентами и разработке стратегии по совершенствованию.
С помощью временных меток команды определяют хронологию инцидента, а также предшествующие события и меры, принятые для его разрешения. Понятная и доступная всем участникам хронология является одним из самых полезных артефактов во время разбора инцидентов.
Время бесперебойной работы
Время безотказной работы — это количество времени (в процентах), в течение которого системы доступны и работоспособны.
С расширением взаимосвязей онлайн-сервисов и ростом сложности самих систем стало понятно, что гарантия безотказной работы в течение 100 % времени невозможна. В случае с большинством продуктов стремятся обеспечить высокую доступность, то есть создать такую систему или продукт, которые могут работать без перерыва в течение длительного времени. Согласно отраслевому стандарту, безотказная работа в течение 99,9 % времени — это очень хороший результат, а в течение 99,99 % — отличный.
Отслеживать значения этого показателя обязательно для выполнения обещаний, данных клиентам. Как и другие показатели, он представляет лишь отправную точку. Если безотказную работу не удается обеспечивать на уровне 99,99 %, для понимания причины потребуется глубже изучить проблему, побеседовать с командой, а также проанализировать процесс, структуру, доступ или технологию.
Чего стоит бояться в аналитике инцидента
У KPI есть недостатки. Так, можно легко попасть в зависимость от малосодержательных данных. Если ваша команда разрешает инциденты недостаточно быстро, для решения проблемы потребуется нечто большее, чем простое осознание этого факта. Вам нужно понимать, как и почему команда решает или не решает проблемы. Кроме того, нужно знать, сопоставимы ли проблемы, которые вы сравниваете.
На основании KPI нельзя понять, как ваши команды подходят к решению сложных задач, почему инциденты происходят все чаще или почему на разрешение инцидента А ушло в три раза больше времени по сравнению с инцидентом Б.
Для этого нужны аналитические выводы. Однако данные могут стать не только отправной точкой на пути к этим выводам, но и преградой. Из-за них может сложиться ложное впечатление эффективной работы, когда показатели не улучшаются. Показатели не учитывают различия (порой весьма существенные) между инцидентами или подходами к их разрешению. Кроме того, за кадром остается опыт ваших команд и фундаментальная сложность самих инцидентов.
«Инциденты гораздо более уникальны, чем принято о них думать. Два инцидента, разрешить которые можно за один промежуток времени, могут значительно различаться по тому, насколько неожиданными и непостижимыми они оказались для ответственных специалистов. Кроме того, меры по смягчению последствий или исправлению ситуации могут нести абсолютно разные риски в разных инцидентах. Инциденты — это не детали с конвейера, у которых показателем качества является ограниченный разброс физических размеров»,
— Джон Оллспоу, «Как уйти от малосодержательных данных об инцидентах» (John Allspaw, Moving Past Shallow Incident Data)
Мы не утверждаем, что KPI неэффективны, и не призываем к отказу от них. Дело в том, что одних только KPI недостаточно. Их нужно использовать как отправную точку. Они помогут выявить причину проблемы и станут первым шагом на сложном пути к эффективному улучшению.
Jira Service Management предлагает возможности создания отчетов, чтобы ваша команда могла отслеживать KPI, а также контролировать и оптимизировать управление инцидентами.
Составление графика дежурств с помощью Opsgenie
С помощью этого руководства вы научитесь настраивать график дежурств, использовать правила переадресации дежурств, настраивать оповещения о начале дежурства, а также изучите другие возможности Opsgenie.
Читать учебное руководствоШаблоны и примеры информирования об инцидентах
Во время реагирования на инциденты становится ясна ценность шаблонов сообщений. Загрузите шаблоны, которые использует наша команда, и познакомьтесь с другими примерами распространенных инцидентов.
Читать статью