

Управление инцидентами для высокоскоростных команд
Создание сборника сценариев для реагирования на инциденты
Используйте в качестве примера наш справочник.
Миссия Atlassian — раскрыть потенциал каждой команды. Что же объединяет все успешные команды? Они используют сборники сценариев для управления многочисленными процессами, чтобы поддерживать бесперебойную работу организации.
В этой статье описаны пять обязательных шагов на пути создания эффективного сборника сценариев по реагированию на инциденты. В качестве шаблона для составления плана реагирования мы воспользуемся справочником Atlassian по управлению инцидентами.
Что такое сборник сценариев по реагированию на инциденты?
Сборники сценариев являются ключевым компонентом управления инцидентами в командах DevOps и ИТ-операций, а также обеспечения кибербезопасности. В них организации устанавливают политики и методики реагирования на незапланированные перебои в работе систем, а команды с их помощью могут преобразовать хаос в порядок и действовать слаженно при устранении инцидентов и угроз безопасности.
В справочнике по управлению инцидентами описан набор процессов, следуя которым, команда может реагировать на инциденты, устранять их и делать из них полезные выводы, будь то проблема безопасности или очередная уязвимость в коде. Справочники могут содержать самую разную информацию, от перечня процедур и контрольных списков до шаблонов, упражнений, сценариев несанкционированного доступа и имитационных учений.
Создание сборника сценариев по реагированию на инциденты
При составлении справочника Atlassian по управлению инцидентами мы определили пять рекомендаций, касающихся управления инцидентами. Их можно адаптировать в различных командах DevOps и ИТ-операций и использовать для разработки эффективного сборника сценариев по реагированию на инциденты.
1. Определите инциденты в вашей организации
Что нужно сделать: дать конкретное определение того, что такое инцидент.
Зачем: эффективно устранять инциденты можно, только точно зная, когда они появляются. Разные команды дают инцидентам разные определения. Когда случается сбой, на счету каждая секунда, и спор между коллегами по поводу терминологии совсем не к месту.
Пример:
Это определение инцидента из справочника Atlassian по управлению инцидентами:
Что такое инцидент?
Мы определяем инцидент как событие, которое приводит к нарушению или снижению качества работы сервиса и требует незамедлительных действий. В командах, которые придерживаются практик ITIL или ITSM, такое событие могут называть «серьезным инцидентом».
Инцидент считается устраненным, когда затронутый сервис возобновляет работу в обычном режиме. Устранение подразумевает только действия, необходимые для восстановления всех функций системы, и не охватывает последующие действия, например поиск и нейтрализацию основной причины, которые совершают при разборе инцидента.
Разбор инцидента выполняется после его устранения и включает выяснение основной причины инцидента и планирование действий для ее устранения, чтобы не допустить повторных инцидентов.
2. Заранее распределите роли
Что нужно сделать: назначить роли и обязанности в рамках реагирования на инциденты.
Зачем: в хорошем сборнике сценариев по реагированию на инциденты четко определены роли и обязанности. С его помощью участники команды реагирования смогут заблаговременно изучить роли и будут в курсе своих обязанностей к моменту возникновения инцидента.
Пример:
Компания Atlassian распределила роли таким образом, чтобы при выполнении всех необходимых действий сотрудники не дублировали работу друг друга, а обмен информацией протекал гладко и эффективно.
- Менеджер инцидентов руководит устранением инцидента и отвечает за результаты. Он уполномочен предпринимать любые действия, необходимые для устранения инцидента. Это подразумевает привлечение к работе над инцидентом любых реагирующих лиц организации и мотивацию всех участников процесса на скорейшее восстановление сервиса.
- Технический руководитель — старший технический специалист, который помогает устранять инцидент. Отвечает за разработку теорий о том, где возникла неисправность и почему, за принятие решений об изменениях и за управление технической частью команды. Исполнитель этой роли тесно сотрудничает с менеджером инцидентов.
- Менеджер по связям — человек с навыками информирования общественности (например, участник команды службы поддержки или команды по связям с общественностью). Отвечает за написание и отправку внутренних и внешних сообщений.
3. Внедрите четкий процесс
Что нужно сделать: определить процедуры и рабочие процессы.
Зачем: двух абсолютно одинаковых инцидентов не бывает. Но это не значит, что реагирующие лица не могут внедрить четкий рабочий процесс для реагирования на инциденты.
Определите основные шаги и этапы и объясните всю цепочку участникам команды, а также то, что от них ожидается в каждый момент. К примеру, в Atlassian процесс реагирования на инциденты разделен на семь шагов, выполняемых в три этапа, что позволяет выполнять все необходимые действия с момента обнаружения инцидента и до его устранения.
Пример:
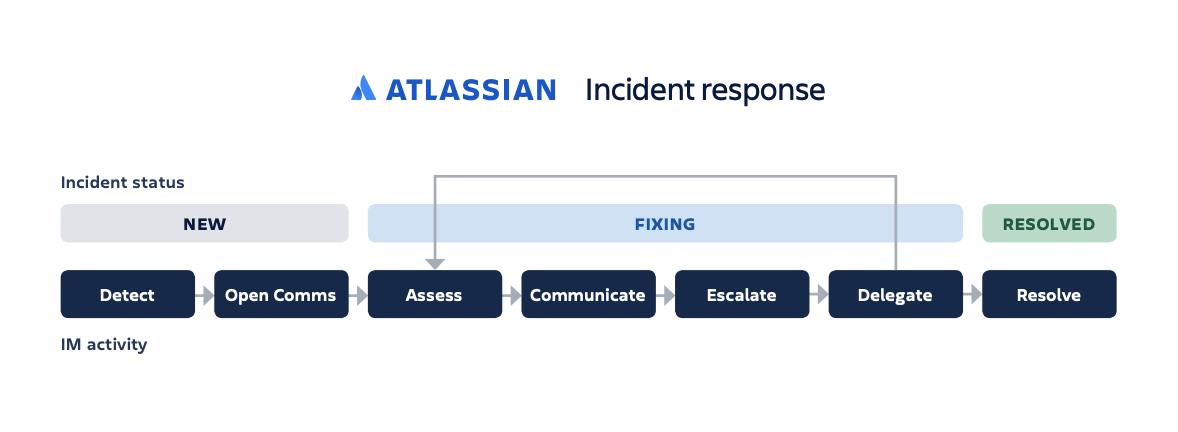
При обнаружении нового инцидента менеджер инцидентов инициирует внутренний обмен информацией и организацию ответных мер. Тогда команда может начать работу над устранением причины инцидента и поиском решения. На этом этапе хорошая организация и коммуникация позволяют действовать эффективно. А следование четкому процессу ускоряет разрешение инцидента, включая проведение ретроспективы, о которой мы поговорим далее.
4. Создайте условия для оперативного реагирования
Что нужно сделать: подготовить шаблоны и контрольные списки.
Зачем: сборники сценариев по реагированию на инциденты должны быть достаточно простыми, чтобы ими можно было воспользоваться в стрессовой ситуации. В нашем процессе предусмотрена «шпаргалка» для менеджера серьезных инцидентов, в которой на одной странице описаны основные шаги, такие как оценка, эскалация и делегирование.
Заранее установленный процесс реагирования на инциденты не означает невозможность импровизировать. Следует действовать гибко и отклоняться от процедуры, когда изменения в ситуации этого требуют. Инциденты по определению являются сценариями, в которых что-то идет не по плану. И тем не менее к ним можно подготовиться. Команды, которые практикуются, отрабатывая набор сценариев, обычно достигают наибольших успехов.
Воспользуйтесь этим ресурсом:
Попробуйте отработать сценарий Ценности при реагировании на инциденты, чтобы усилить сплоченность команды и устранить любые возможные недопонимания еще до того, как столкнетесь с инцидентом. Используйте наш ресурс Atlassian Team Playbook, чтобы лучше понять процесс команды и составить собственный динамический сборник сценариев.
5. Проводите всесторонний разбор инцидентов
Что нужно сделать: определить процесс разбора инцидентов и поля задач.
Зачем: цель разбора инцидента заключается в том, чтобы извлечь из него максимум пользы, в том числе узнать обо всех его причинах, задокументировать инцидент для дальнейшей работы и выявления закономерностей, а также принять эффективные профилактические меры, чтобы уменьшить вероятность повторения инцидента либо смягчить его последствия, если ситуация все же повторится.
Если рассматривать инцидент как внеплановую инвестицию в надежность системы, то его разбор — это способ максимально увеличить окупаемость этого вложения.
Попробуйте сделать следующее:
Чтобы разбор инцидентов был эффективен, эта процедура должна упрощать поиск и устранение причин инцидента для команд. Выбор конкретного метода работы зависит от культуры вашей команды. В Atlassian мы подобрали сочетание методов, которые подходят нашим командам по разбору инцидентов.
- Очные совещания позволяют выполнить необходимый анализ и согласовать с командой перечень проблем, которые нужно исправить.
- Предстоящее утверждение итогов разбора руководителями команды поставки и операционной команды побуждает проводить разбор инцидента очень тщательно.
- К назначенным приоритетным действиям привязываются цели по уровню обслуживания (SLO), а также напоминания и отчеты, чтобы их выполнение можно было легко отследить.
Пошаговое описание процесса Atlassian для разбора по итогам реагирования на инцидент находится на странице 46 справочника по управлению инцидентами.
Сборник сценариев по реагированию на инциденты используют главным образом для того, чтобы научить команды действовать согласованно и эффективно для максимально быстрого устранения инцидентов. Когда возникает инцидент, нет времени на споры о том, кто виноват и что теперь делать. Подробные и продуманные сборники сценариев помогают командам избежать разногласий и достичь успеха. Детальное руководство по всем указанным сценариям вы найдете в справочнике Atlassian по управлению инцидентами.
Составление графика дежурств с помощью Opsgenie
С помощью этого руководства вы научитесь настраивать график дежурств, использовать правила переадресации дежурств, настраивать оповещения о начале дежурства, а также изучите другие возможности Opsgenie.
Читать учебное руководствоПлюсы и минусы различных подходов к управлению дежурствами
Дежурные команды быстро развиваются. Узнайте о плюсах и минусах различных подходов к управлению дежурствами.
Читать статью